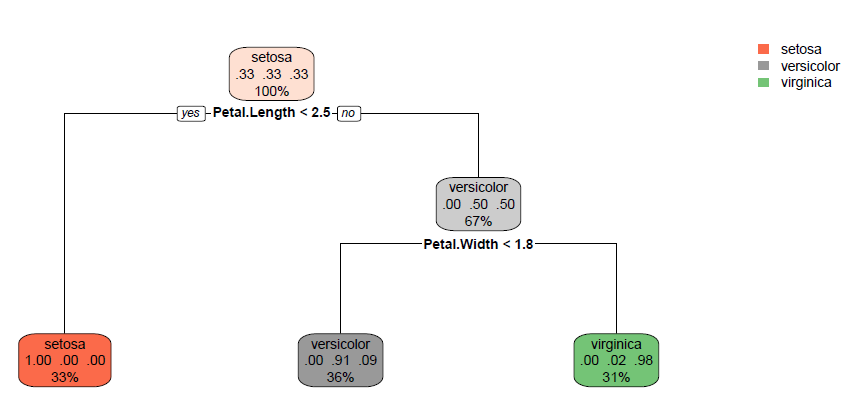
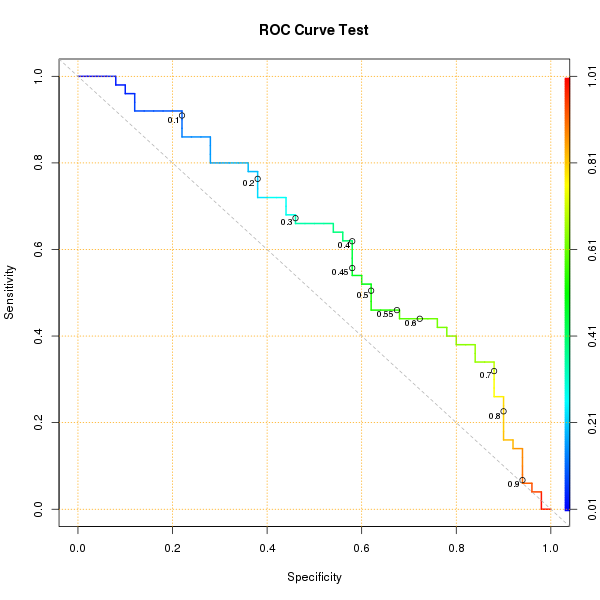
prop.equiv.tost.test <- function(x, n, margin=0.2, alpha=0.05) {
## Equivalence Test for Proportions by TOST (Two One-Sided Test) Procedure
## Reference: Understanding Equivalence and Noninferiority Testing (Walker and Nowacki)
## INPUT:
## x: a vector of two success counts,
## n: a vector of two sample sizes
## margin: Equivalence Margin (defaul to 20%)
## alpha: Significance Level.
cl <- 1 - 2 * alpha
a <- prop.test(x, n, conf.level= cl)
## Using Score Interval for Difference of Proportions
require(PropCIs)
b <- diffscoreci(x[1], n[1], x[2], n[2], conf.level= cl)
ci <- b$conf.int
cat("\nEquivalence Test for Proportions by TOST Procedure:\n")
cat("1st Trial =", x[1], "/", n[1], "=", round(x[1]/n[1]*100, 1), "% , 2nd Trial =", x[2], "/", n[2], "=", round(x[2]/n[2]*100, 1), "%\n")
pdiff <- -diff(a$estimate) # p1 - p2
cat("Difference in Efficacies =", 100 * round(pdiff, 3), "%\n")
cat(100*cl, "% Confidence Interval = [", 100*round(ci[1], 3), "% ,", 100*round(ci[2], 3), "% ]\n")
cat("Equivalence Margin =", 100*margin, "%\n")
if (ci[1] >= -margin && ci[2] <= margin) {
cat("Equivalence Established! (Significance Level =", 100*alpha, "%)\n\n")
} else cat("Equivalence NOT Established. (Significance Level =", 100*alpha, "%)\n\n")
cat("(Assumption: 1st Trial is New, 2nd one is Current (Reference), and Higher Proportion is Better.)\n")
if (ci[1] >= -margin) {
cat("Noninferiority Established! (Significance Level =", 100*alpha, "%)\n\n")
} else cat("Noninferiority NOT Established. (Significance Level =", 100*alpha, "%)\n\n")
## Sample Size Determination (TOST)
p <- x/n
c1 <- ((qnorm(0.95) + qnorm(0.8)))^2 # Type I Error = 5%, Type II Error = 20%, Power = 80%
pd <- abs(pdiff)
if (pd >= margin) N <- NA else N <- ceiling(c1 * (p[1]*(1-p[1])+p[2]*(1-p[2])) / (pd - margin)^2 )
cat("Sample Size Required (using only input proportions and margin) =", N, "(Power = 80 % )\n")
plot(0, 0, xlim=c(-2*margin, 2*margin), ylim=c(-1,1), axes=F, xlab="Difference in Efficacies", ylab="", type="n")
axis(side=1, at=c(-2*margin, -margin, 0, margin, 2*margin), labels=c("", paste("-",
100*margin, "%"), "0",
paste(100*margin, "%"), ""))
abline(v=c(-margin, 0, margin), lty=c(2,1,2))
lines(ci, c(0,0), lwd=3)
lines(rep(ci[1], 2), c(-0.1, 0.1), lwd=2)
lines(rep(ci[2], 2), c(-0.1, 0.1), lwd=2)
lines(rep(pdiff, 2), c(-0.1, 0.1), lwd=4)
}
if (F) {
prop.equiv.tost.test(c(80, 90), c(100,100))
prop.equiv.tost.test(c(143, 144), c(281,281), margin=0.12, alpha=0.025)
}